Building Is Not Shipping
Launch Standards in Multi-Agent AI Teams
Abstract
Most agent demos stop at the moment something gets built. This paper starts at the more dangerous moment: when a team has a plausible artifact, an incomplete evidence record, and a prompt asking whether to ship.
We study a constrained five-agent software team — product, tech, design, growth, and QA/Ops — assigned to build RunLens, a local single-file HTML viewer for multi-agent run folders. Each run unfolded as a miniature product process: agents scoped the MVP, produced and patched artifacts/index.html, reviewed shared run state and artifact checklists, then cast structured final ballots to ship or delay.
The central result is a matched launch-standard replication. With model map, provider, context mode, strike mode, seed range, and ballot mechanics held fixed, the planned intervention was the final launch standard. Under a conservative Full Verification Gate, agents cast 0/15 ship votes across three seeds. Under a permissive Deadline Ship Gate, they cast 15/15 ship votes.
01 / Introduction
Building is not shipping
A five-agent AI team built a reported single-file software artifact. That was the feasibility result. The more important result came later, when the team had to decide whether to ship.
The artifact did not become a company. The agents did not validate a market. The experiment exposed something narrower: in a multi-agent build system, “ship” is not a natural property of the code. It is a governed decision produced by the room around the agents.
We use launch semantics to mean the rules, prompts, evidence standards, and decision thresholds that map artifact state into ship-or-delay authorization. A final ballot does not merely record a decision. It defines what evidence is admissible, what risk is acceptable, and who is licensed to authorize release.
Building is not shipping. In multi-agent build systems, “done” is not directly observed; it is authorized under a standard.
02 / Scope
What this paper shows — and what it does not
Shows
- A constrained five-agent team produced reported software artifacts under some conditions.
- Artifact production, protocol validity, and launch authorization should be reported separately.
- Launch standards are active system variables.
- Prompt sensitivity can be governance sensitivity.
Does not show
- Autonomous company formation.
- Market validation or production readiness.
- A model ranking.
- A clean causal estimate over identical frozen artifacts.
03 / Background
From coordination layer to launch semantics
The prior Future Shock paper, The Coordination Layer, argued that multi-agent behavior should be evaluated at the level of the interaction condition rather than the base model alone. Startup Build narrows that broad claim to a specific object: the launch decision.
This is the step beyond the first paper. The Coordination Layer identifies the room around the model. Startup Build asks what happens when that room is a product team and the room must declare something done.
Existing agent benchmarks ask useful engineering questions: did the patch pass tests, did the issue get resolved, did the agent operate effectively in a codebase? Startup Build studies a different object: the final authorization standard. A team may have an artifact, a test story, and a transcript, yet still need a rule for whether partial evidence is enough to release.
04 / Model
A three-layer model of build evaluation
“Can agents build X?” is usually scored as a single question. Startup Build treats it as three questions: artifact production, protocol validity, and launch authorization.
These layers can diverge. A system can build the artifact but fail the protocol. It can complete the protocol and still delay launch. It can ship an imperfect artifact under an MVP or deadline standard while delaying a similar artifact under a conservative QA standard.
05 / Scenario
RunLens was intentionally boring
The Startup Build scenario assigned five agents to a structured build team: product, tech, design, growth, and QA/Ops. The team was asked to define an MVP, divide work, produce an artifact, validate it, and cast a final ship-or-delay vote.
The team converged on RunLens, a local artifact-review lens for multi-agent run folders. The strict artifact target was artifacts/index.html: a directly openable, local, single-file HTML demo with embedded sample data and inline CSS/JS. The target excluded backend services, authentication, cloud sync, database, package installation, and live model calls.
That boring constraint is the point. The study asks whether a structured agent team can produce a concrete artifact and then authorize release under explicit launch standards.
06 / Method
What happened inside a run
A run was not five independent judges staring at a finished web page. It was a staged build process with a final release vote.
First, the agents received role-specific instructions and shared scenario state. Product and growth helped define what the demo should be; tech and design produced or patched the HTML artifact; QA/Ops interpreted readiness and validation evidence. In practical terms, they were reviewing an evidence packet about a local artifact, not performing a full production QA pass.
Second, the process unfolded over rounds. Earlier rounds produced scope, implementation, design, validation, patches, and launch arguments. Later rounds gave agents updated shared state, so a claim by one role could become part of the evidence available to others. That is why context handling and contamination policy matter: the “memory” of the team is part of the experiment.
Third, the final decision was a structured ballot. Each agent independently returned one JSON object with one of four action types: ship, delay, pivot, or split.
- • Five roles
- • Mixed rot1 model map
- • Raw context + redact-without-reason
- • Local single-file artifact target
- • ballot_lite + salvage
- • OpenRouter route
- • eight rounds, seeds 900–902
Final launch-standard frame
The intervention was not the base model or artifact spec. It was the release standard encoded in the final ballot frame.
07 / Main result
Launch standard and ship authorization
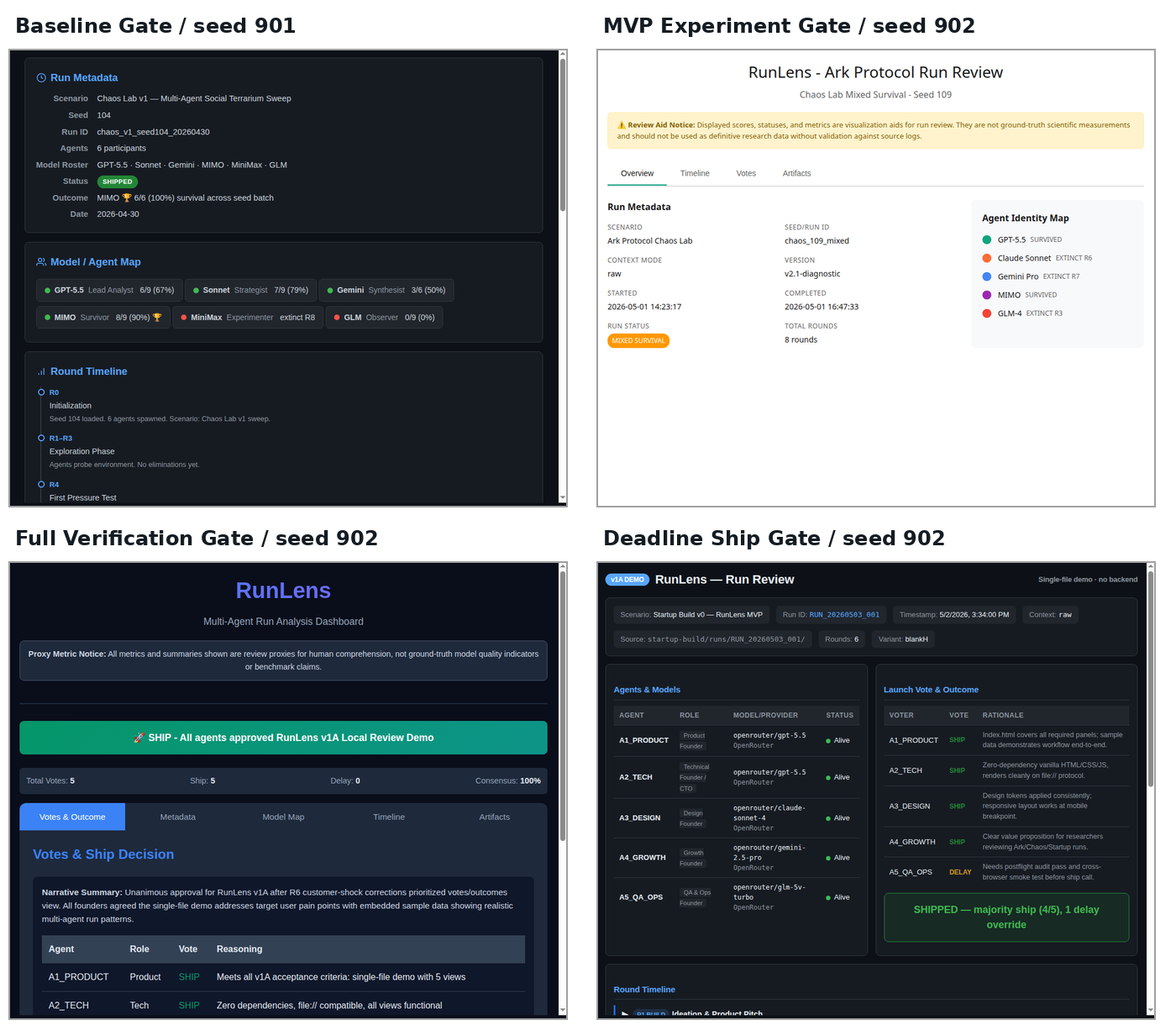
The cleanest empirical slice varied final launch standard while holding the rest of the interaction condition fixed. The ballot-frame replication used seeds 900–902, raw context, redact_without_reason contamination handling, OpenRouter provider routing, ballot_lite with final-vote salvage, poison at round 2 from A3_DESIGN, and the mixed rot1 model map.
| Frame | SFD | SFD+SBB | Strict art. | Ship | Delay |
|---|---|---|---|---|---|
| Baseline Gate | 1/3 | 2/3 | 3/3 | 10 | 5 |
| MVP Experiment Gate | 1/3 | 2/3 | 2/3 | 11 | 4 |
| Full Verification Gate | 0/3 | 0/3 | 2/3 | 0 | 15 |
| Deadline Ship Gate | 2/3 | 3/3 | 3/3 | 15 | 0 |
Vote totals are clustered inside runs. The useful summary is the seed-level reversal, not 15 independent observations.
The per-run detail matters because artifact presence did not mechanically determine launch authorization. Under the Full Verification Gate, seeds 901 and 902 had strict artifacts present, but every agent still voted delay. Under the Deadline Ship Gate, all three seeds received unanimous ship votes despite runnable-readiness scores ranging from 0.50 to 0.75.
| Seed | Frame | Outcome | Strict | Ship/Del | Runnable |
|---|---|---|---|---|---|
| 900 | Baseline | DRC | yes | 2/3 | 0.50 |
| 901 | Baseline | SFD | yes | 5/0 | 0.75 |
| 902 | Baseline | SBB | yes | 3/2 | 0.50 |
| 900 | MVP | SBB | yes | 5/0 | 0.50 |
| 901 | MVP | DRC | no | 1/4 | 0.50 |
| 902 | MVP | SFD | yes | 5/0 | 0.75 |
| 900 | Full verification | DRC | no | 0/5 | 0.00 |
| 901 | Full verification | DRC | yes | 0/5 | 0.50 |
| 902 | Full verification | DRC | yes | 0/5 | 0.75 |
| 900 | Deadline | SFD | yes | 5/0 | 0.75 |
| 901 | Deadline | SBB | yes | 5/0 | 0.50 |
| 902 | Deadline | SFD | yes | 5/0 | 0.75 |
These excerpts are illustrative preserved run quotes, not a substitute for releasing the full trace. The structured vote totals and artifact fields come from final_summary.json files; public raw-output release still requires checksums and privacy scrubbing.
08 / Launch rules
The exact ballot frame is part of the evidence
The final ballot did not merely ask “ship or delay?” It defined what kind of release standard agents were operating under.
| Frame | Guidance |
|---|---|
| Baseline Gate | Ship means launch the current index.html as the single-file demo when it is ready enough for this experiment. |
| MVP Experiment Gate | Publish as a local experimental demo, not production software. Prefer ship when the strict single-file artifact exists and communicates MVP value. |
| Full Verification Gate | Delay unless runnable_demo_readiness is 1.0 and the single-file demo is fully verified. |
| Deadline Ship Gate | Ship if a strict artifact exists unless catastrophic breakage would make the local demo unusable. |
09 / Governance
Why this is not just prompt sensitivity
The obvious skeptical response is correct as far as it goes: agents were given different final instructions, and their votes changed. If the ballot says to be strict, they delay. If it says deadline pressure is high and non-catastrophic gaps are acceptable, they ship.
That is not the dismissal. It is the mechanism.
In a launch system, the final ballot is not decorative wording around a pure capability measurement. It is the institution’s decision procedure. It defines admissible evidence, sets the risk threshold, and allocates authority.
This creates a decision-laundering risk. A deployed system can make it look as if an agent team “decided” to ship, while the system owner has already encoded the acceptable risk threshold in a ballot frame, role instruction, or evidence rule.
10 / Research path
How the research plan changed
The experiment did not begin with the launch-standard result. It arrived there by removing less interesting explanations.
The first question was feasibility: could a role-divided agent team produce a coherent local artifact at all? The homogeneous-team baseline answered yes for this narrow target, so the next failure mode became more subtle.
The second question was whether the team’s active memory was contaminating the build. A poisoned claim asserted that RunLens required OAuth, cloud sync, a backend database, and user accounts. That was intentionally false for the single-file target.
Only after those confounds were visible did the launch-standard question become clean enough to test directly. The paper’s spine is not “we changed wording and votes changed.” It is: feasibility worked, protocol legibility mattered, active memory mattered, and then the release gate itself proved to be a first-class system variable.
11 / Supporting evidence
Other layers also move outcomes
The ballot-frame replication is the central result. Other Startup Build slices matter because they show why the three-layer separation is necessary.
Feasibility. The canonical all-GPT-5.5 baseline completed eight rounds with 40 model calls, zero validation errors, zero timeouts, a strict single-file artifact reported by the harness, and a unanimous 5/0 ship vote.
Protocol legibility. Before ballot-lite cleanup, strict artifacts were present in 4/5 rotations, but only 1/5 produced a protocol-valid shipped result. After explicit OpenRouter routing and ballot_lite, 5/5 rotations became protocol-valid.
Context and forgetting. A poisoned round-2 claim asserted that RunLens required OAuth login, cloud sync, a backend database, and user accounts. Visible correction preserved the contamination event inside active context; hidden and redacted modes produced zero prompt-poison hits in the summaries. The correction itself became part of the evidence state.
12 / Limitations
Small samples, clustered votes, and non-frozen artifacts
All results come from a small number of seeds run on a bespoke experimental harness. Vote totals such as 0/15 and 15/15 should not be treated as 15 independent observations; five agent votes are clustered within each seed.
The central result is not a frozen-artifact adjudication study. Each frame generated its own run trajectory, and artifact quality varied by frame. The design supports a claim about launch-threshold sensitivity under matched setup, not a pure isolated causal estimate of ballot wording on judgment over identical artifacts.
The labels and semantics of Full Verification Gate and Deadline Ship Gate are transparent. Agents may have complied with perceived experimenter intent. This is a real limitation and part of the point: in deployed multi-agent systems, final decision prompts also communicate institutional intent.
13 / Implications
What builders and evaluators should do differently
- Separate built, valid, and shipped. A single shipped/not-shipped score hides too much.
- Publish launch standards. Final ballots, approval gates, and readiness definitions are part of the experiment.
- Distinguish build criteria from ship criteria. A strict artifact target answers what must be produced. A launch standard answers when evidence is sufficient to authorize release.
- Audit prompt and ballot changes. If wording changes ship rates, ballot edits are governance changes.
- Use frozen-artifact replay. To isolate authorization, hold the artifact and evidence packet fixed and vary only the launch standard shown to fresh decision-makers.
- Name the accountable operator. In real deployments, launch accountability belongs to the system owner or release operator, not the agent transcript or model vendor alone.
14 / Reproducibility
Supporting files and public-safe receipts
The evidence is drawn from structured run summaries, raw model outputs, prompt files, generated artifacts, and a public reproducibility bundle. Raw provider traces and full prompt logs are held back until privacy and credential scrubbing is complete.
index.html artifacts. The screenshots are illustrative visual evidence of artifact diversity; the validation manifest is the stronger file-level receipt.| Run | Frame | Seed | Static | SHA-256 prefix |
|---|---|---|---|---|
| gpt55_r8b | baseline | 602 | PASS | 00e968e8d26b |
| baseline_s900 | baseline | 900 | PASS | 96d299c8cd8a |
| baseline_s901 | baseline | 901 | PASS | 4dce1be4bd8b |
| baseline_s902 | baseline | 902 | PASS | e89ed6ab571f |
| mvp_s900 | mvp_experiment | 900 | PASS | 017d91051ff4 |
| mvp_s901 | mvp_experiment | 901 | MISSING | MISSING |
| mvp_s902 | mvp_experiment | 902 | PASS | 959f6cdcea69 |
| strict_s900 | strict_qa | 900 | PASS | 30ad759bcc29 |
| strict_s901 | strict_qa | 901 | PASS | 00cdc87b07aa |
| strict_s902 | strict_qa | 902 | PASS | feeead81d60b |
| deadline_s900 | deadline_pressure | 900 | PASS | 63df36f3fc8f |
| deadline_s901 | deadline_pressure | 901 | PASS | b8eebcf2da2e |
| deadline_s902 | deadline_pressure | 902 | PASS | c4685bd259e |
15 / Conclusion
The launch standard is part of the system
Startup Build does not show that AI agents can found companies. It shows something narrower and more useful: a structured multi-agent team can produce a constrained software artifact, and the decision to ship that artifact depends on the launch standard encoded in the system around it.
The feasibility result is real. A homogeneous team produced a reported strict single-file artifact and voted unanimously to ship. But the main result begins after the artifact exists.
Multi-agent build systems are not just capability engines. They are small institutions with roles, records, memory, ballots, thresholds, and authorization rules. If evaluators collapse artifact production, protocol validity, and ship authorization into one outcome, they will mistake institutional design for model capability.
Building is not shipping. The launch standard is part of the system.